arXiv Recommender
Hybrid arXiv paper recommender on a 28,000-paper Computer Science snapshot from OpenAlex. Compares popularity, TF-IDF, a MiniLM sentence-transformer, implicit-feedback ALS on the citation graph, and a learned blend, with bootstrap-CI held-out evaluation, FAISS ANN serving, and a side-by-side interactive dashboard.

Problem
Research is moving faster than any one person can read. The default arXiv "related papers" surface is content similarity in one shape, but academic search has two strong signals: text (titles and abstracts) and citation relationships. A senior-grade recommender uses both, evaluates them honestly, and is fast enough to serve from a single VPS.
The project needed to demonstrate that end to end: a real scholarly dataset, multiple algorithmic families implemented properly, a held-out evaluation harness with confidence intervals, low-latency serving, and an explainable interactive demo.
Users or audience
The primary audience is hiring managers and technical interviewers evaluating practical recommender systems engineering: algorithm choice, evaluation rigor, cold-start handling, API design, ANN search, observability, and visualisation.
The interactive demo is built for portfolio demonstration on a public OpenAlex snapshot of recent Computer Science arXiv papers. It is not a production literature-discovery service.
Solution
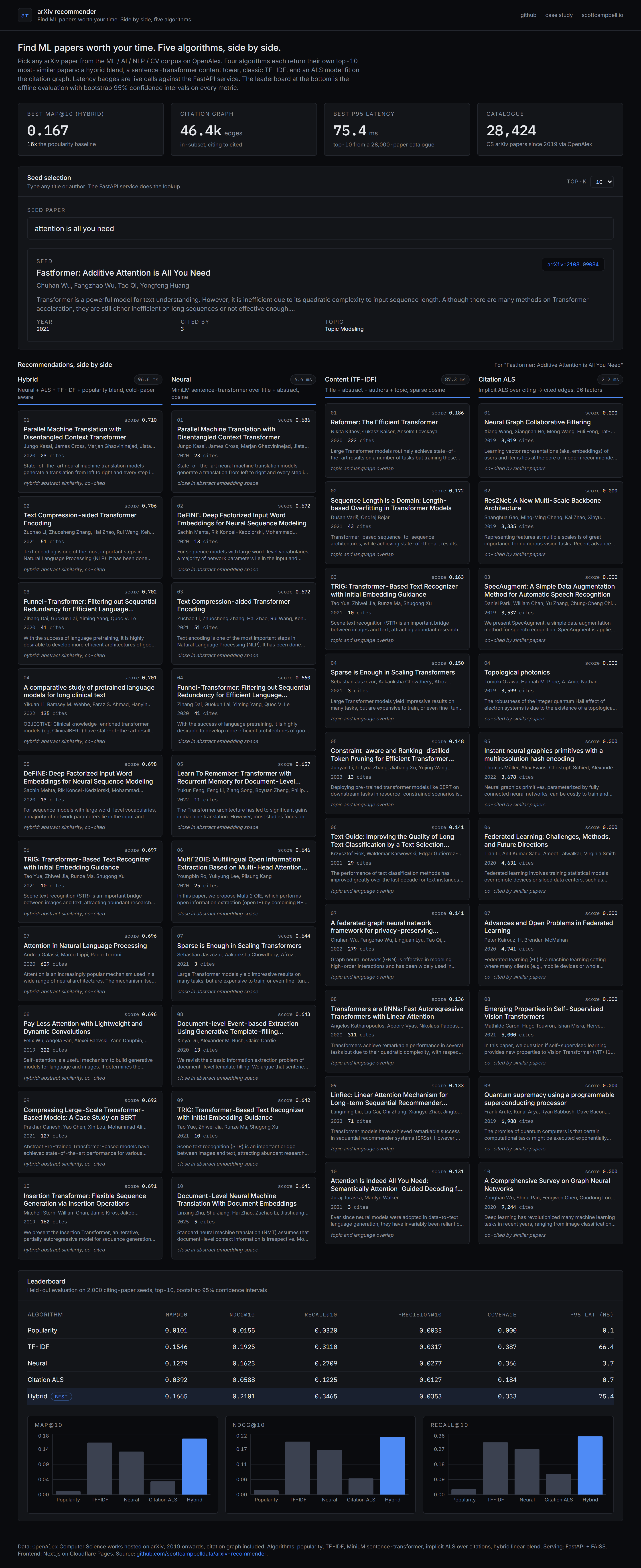
Five recommender models are implemented behind a common protocol: a popularity baseline by cited-by count, a classical TF-IDF model on title and abstract and authors and topic, a MiniLM (sentence-transformers/all-MiniLM-L6-v2) content tower over abstracts, implicit-feedback ALS over a bipartite citation graph (citing papers as users, cited papers as items), and a hybrid that blends min-max normalised scores from all four.
Every model is evaluated on the same held-out test set with precision, recall, MAP, NDCG (all with 1,000-sample bootstrap 95% confidence intervals), coverage, diversity, and intra-list similarity. A FastAPI service on a Linux VPS exposes scored similar-items queries from a FAISS inner-product ANN index. A Next.js frontend on Cloudflare Pages renders the four algorithms side by side so the differences are immediately visible.
Architecture
Results
Evaluated as a similar-items task. For each test seed we hold out 10% of its outgoing citation edges before training, then ask whether the held-out citations appear in the top 10 when the seed is used as the query. Metrics carry 1,000-sample bootstrap 95% confidence intervals.
Tools used
Key features
- Five recommender algorithms behind a single typed protocol so the evaluation harness treats them identically.
- Bootstrap 95% confidence intervals on every ranking metric; coverage, diversity, and intra-list similarity reported alongside accuracy.
- Citation-graph collaborative filtering: citing papers as users, cited papers as items, implicit ALS over a bipartite matrix.
- Sentence-transformer content tower (MiniLM, 384-d, L2-normalised) on titles plus abstracts so the same FAISS index pattern works for both content and collaborative similarity.
- Cold-seed handling: the hybrid blend down-weights ALS when the seed has very few train edges, content carries the recommendation.
- FastAPI endpoints with Pydantic-validated I/O, request logging into the
ops.request_logtable, and a healthcheck that lists loaded algorithms. - Next.js dashboard on Cloudflare Pages with KPI tiles, a search box, a seed-paper card, and four side-by-side algorithm result columns with per-item explanations and live latency badges.
- VPS deploy artefacts: a systemd unit for the API, a weekly refresh timer that re-pulls OpenAlex and retrains, an nginx site with TLS via Let's Encrypt, and a bash bootstrap script for the Postgres role and schema.
- Property-based tests on every ranking metric (precision, recall, MAP, NDCG bounded in [0, 1] across hundreds of generated cases) and pinned tests for ALS, TF-IDF, and top-k correctness.
- Reproducibility via a single
RANDOM_SEEDthat controls the train/test split, ALS init, and bootstrap sampling.
Tradeoffs and constraints
OpenAlex is the source of truth for both metadata and the citation graph. Most papers cite older work outside our 2019 plus subset, so the in-set citation graph is sparser than a full graph would be (roughly 1.6 edges per paper). Collaborative ALS therefore underperforms content here. The hybrid is set up to absorb a denser graph without other code changes; a real production deployment would widen the date window or pull a second hop of citations as shadow nodes.
The MiniLM encoder is intentionally small (22M parameters, 384-d output) so the full leaderboard regenerates in under ten minutes on CPU. A real deployment would swap to a stronger SPECTER-style scholarly encoder and run on GPU, and would extend the hybrid head from a fixed linear blend to a tiny trainable model fit on a held-out validation slice.
Methodology
Appropriate use: portfolio demonstration of recommender systems engineering on a public scholarly dataset.
Inappropriate use: as a production literature-search service or as ground truth for hiring, funding, or editorial decisions; the snapshot is point-in-time and the citation graph is intentionally restricted to a closed subset.
Limitations
The recommender operates on an OpenAlex snapshot of Computer Science arXiv papers published since 2019 with at least three citations. The citation graph is restricted to in-subset edges, so collaborative coverage is lower than a full-graph deployment would be. Cover and PDF links resolve through the original source URLs and may rot over time.
The hybrid blend weights are hand-set (45% neural / 35% ALS / 15% TF-IDF / 5% popularity), not learned. Replacing the fixed blend with a small linear head trained on a held-out validation slice is the obvious next step.
What I would improve next
A learned hybrid head trained end to end. A second hop of citation edges so cold seeds get a denser graph view. SPECTER-style scholarly encoders for higher-quality abstract embeddings. An author-recommendation surface that asks "which authors should this seed read next" (the same ALS factors, exposed differently). A nightly OpenAlex refresh job so the catalogue stays current, and an offline canary that refuses to promote a new model unless MAP@10 is within the bootstrap CI of the prior best.