Automotive Analyst
A bring-your-own-key text-to-SQL agent for the synthetic manufacturing warehouse. The browser calls Claude, OpenAI, or Gemini directly, while the backend serves schema context and safely runs read-only PostgreSQL with visible guardrails.
Evidence
Screenshots from the live app showing the BYOK panel, natural-language sample questions, and the guarded execution workflow.
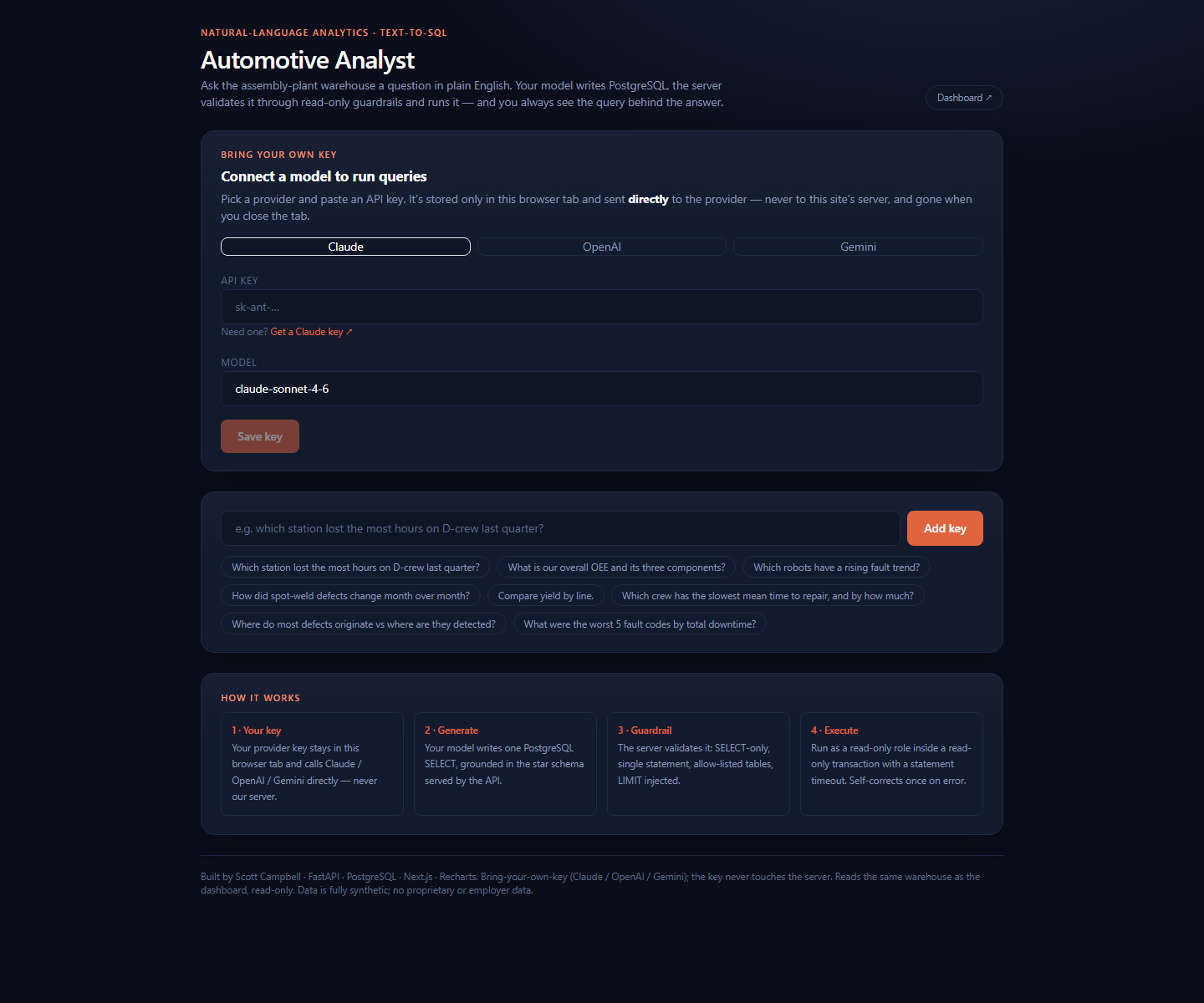
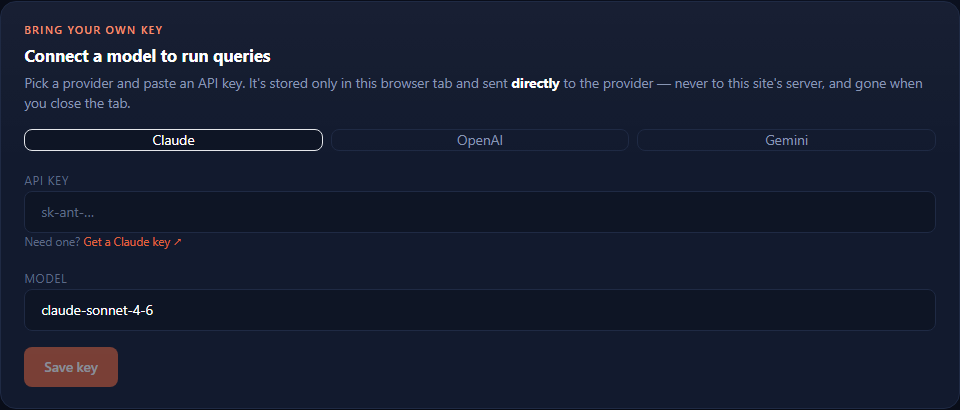
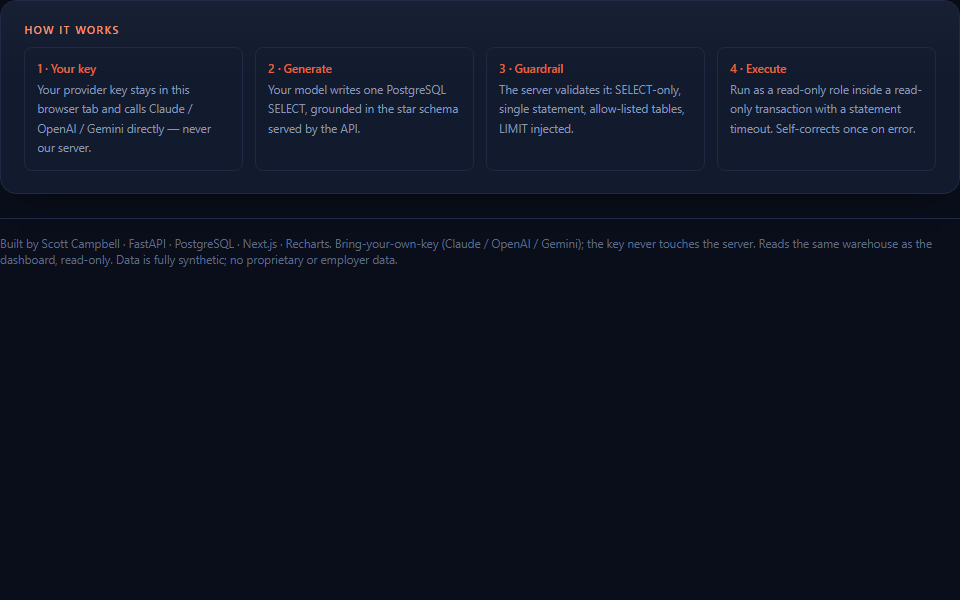
Problem
Manufacturing data warehouses answer valuable questions, but most users cannot translate an operations question into correct SQL quickly. A plain-English analyst can help, but generated SQL against a database needs stronger safety boundaries than a typical chat demo.
The project needed to let a visitor ask questions over the synthetic factory warehouse while keeping the LLM key out of the backend and preventing writes, catalog access, chained statements, or runaway queries.
Users or audience
The primary audience is recruiters, hiring managers, and technical interviewers evaluating full-stack AI integration, SQL safety, provider abstraction, backend guardrails, and practical analytics UX.
The app is a portfolio companion to the Manufacturing Intelligence Platform. It uses the same synthetic warehouse read-only and is not connected to proprietary or employer data.
Solution
Automotive Analyst uses a bring-your-own-key model. The visitor selects Claude, OpenAI, or Gemini, and the browser sends the schema-grounded prompt directly to that provider. The generated SQL is then posted to the backend for validation and execution.
The backend holds no LLM secret. Its job is deliberately narrower: serve schema context, validate SQL through an allow-list guardrail layer, execute inside a read-only transaction using a read-only database role, and return the answer with the exact SQL shown.
Architecture
Data flow
The browser loads sample questions and schema context from the API. When a visitor asks a question, the browser calls the chosen model provider directly and receives SQL text.
The backend accepts the question and SQL, validates the SQL, injects a default limit when needed, executes safely against the synthetic warehouse, and returns columns, rows, a visualization hint, the guardrail verdict, and the final SQL.
Tools used
Key features
- Bring-your-own-key provider panel with session-only key storage.
- Client-side provider abstraction for Claude, OpenAI, and Gemini.
- Schema context and few-shot examples served by the API for grounded SQL generation.
- Fail-closed SQL guardrails for single-statement, read-only, allow-listed queries.
- Dedicated read-only database role, read-only transaction, statement timeout, rate limits, and request size caps.
- Exact SQL returned with each answer so the user can audit what was run.
- Self-correction path when a generated query fails database execution.
Safety model
The project treats client-supplied SQL as untrusted by default. The app layer rejects chained statements, write operations, admin functions, catalog access, unknown tables, comment obfuscation, and unsafe query shapes before anything reaches the database.
The database then provides a second boundary: execution happens through a dedicated read-only role inside a read-only transaction with a timeout. Even if the app guardrail missed something, the database role is still not allowed to write.
Methodology
The agent reads the same synthetic manufacturing warehouse as the factory dashboard. Sample questions cover station downtime, OEE, robot fault trends, monthly defect movement, yield comparison, crew repair speed, and defect origin versus detection.
The guardrail test suite covers attack cases including statement chaining, destructive SQL, catalog probes, file reads, information schema access, COPY-style exfiltration, comment hiding, and false-positive keyword traps.
Results or expected value
The project demonstrates how to expose an AI analytics interface without asking the backend to hold model keys or trust generated SQL blindly.
Limitations
This is a portfolio demonstration over synthetic data. The user must provide a model key, and answer quality depends on the provider model, schema prompt, and generated SQL.
A production version would add authentication, durable audit logs, richer semantic modeling, stricter cost controls, saved approved queries, and more extensive evaluation of generated SQL accuracy.
What I would improve next
I would add query fingerprints, an approval layer for common executive questions, expanded SQL accuracy evaluations, richer chart recommendations, and a deeper data dictionary so non-technical users can ask better follow-up questions.