Book Recommender
Hybrid book recommendation system on the Goodbooks-10k corpus (10,000 books, 5.9M ratings, 53,366 users). Compares popularity baseline, TF-IDF content, implicit-feedback ALS, a neural two-tower model, and a learned blend, with held-out evaluation, bootstrap confidence intervals, FAISS ANN serving, and a side-by-side interactive demo.

Problem
Recommender systems are one of the highest-value BI surfaces in any business that has a catalogue and engagement data, and they need to handle three concrete realities at the same time: dense head users with rich behaviour, brand-new cold users with no behaviour at all, and the long tail of items that few people have rated. A senior-grade recommender is not a single model; it is a portfolio of models with a defensible evaluation harness around them.
The project needed to demonstrate that portfolio end to end: data into a relational store, multiple algorithmic families implemented properly, a real evaluation framework with confidence intervals, cold-start handling, low-latency serving, and an explainable interactive demo.
Users or audience
The primary audience is hiring managers and technical interviewers evaluating practical recommender systems engineering: algorithm choice, evaluation rigor, cold-start handling, API design, ANN search, observability, and visualisation.
The interactive demo is built for portfolio demonstration on the public Goodbooks-10k dataset. It is not a production reading service.
Solution
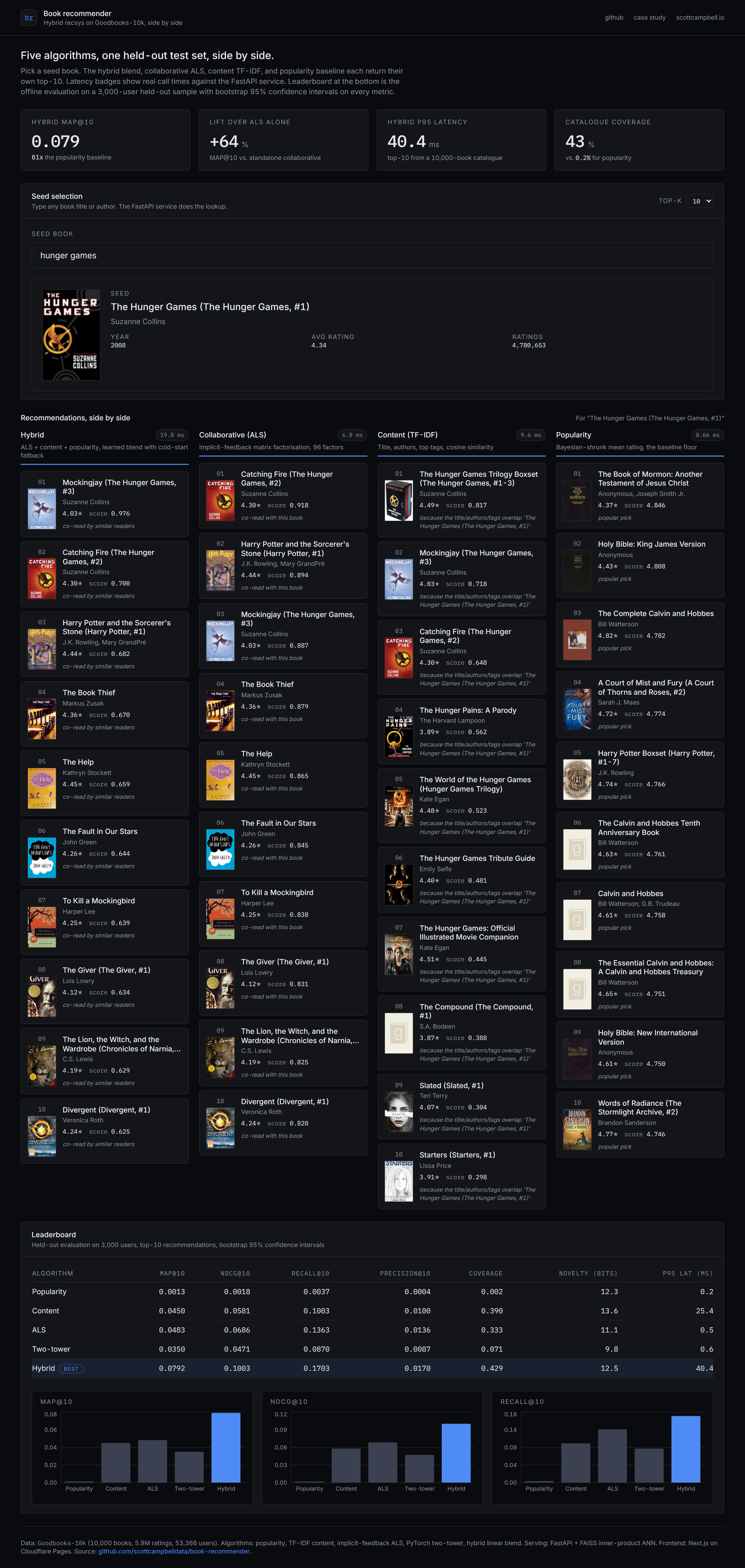
Five recommender models are implemented behind a common protocol: a Bayesian-shrunk popularity baseline, a TF-IDF content model on title and author and tags, implicit-feedback ALS via the implicit library with rating-weighted confidence, a small PyTorch two-tower with weighted BPR loss, and a hybrid that blends normalised scores with explicit cold-user fallback.
Every model is evaluated on the same held-out test set with precision, recall, MAP, NDCG (all with 1,000-sample bootstrap 95% confidence intervals), coverage, novelty, diversity, and intra-list similarity. Cold users are reported as a separate segment. A FastAPI service on the VPS exposes scored similar-items and per-user recommendations from a FAISS ANN index built over the ALS and content vectors. A Next.js frontend on Cloudflare Pages renders the four algorithms side by side so the differences are immediately visible.
Architecture
Results
Evaluated on a 3,000-user held-out sample (each user's one held-out positive rating). All metrics carry 1,000-sample bootstrap 95% confidence intervals; coverage and latency are over the full rec lists.
Tools used
Key features
- Five recommender algorithms behind a single typed protocol so the evaluation harness treats them identically.
- Bootstrap 95% confidence intervals on every ranking metric; coverage, novelty, diversity, and intra-list similarity reported alongside accuracy.
- Explicit cold-user segment (bottom-quartile train history) and cold-item segment with separate metrics.
- Cold-start logic in the hybrid: when a user has no train history, weights collapse to a content-plus-popularity blend instead of zero-vector collaborative noise.
- FAISS inner-product ANN over ALS item factors and a 256-dim truncated SVD of the TF-IDF vectors for sub-millisecond similar-items lookup.
- FastAPI endpoints with Pydantic-validated I/O, request logging into the
ops.request_logtable, and a healthcheck that lists loaded algorithms. - Next.js dashboard on Cloudflare Pages with KPI tiles, a search box, a seed-book card, and four side-by-side algorithm result columns with per-item explanations and live latency badges.
- VPS deploy artefacts: a systemd unit for the API, a weekly retrain timer, an nginx site with TLS via Let's Encrypt, and a bash bootstrap script for the Postgres role and schema.
- Property-based tests on every ranking metric (precision, recall, MAP, NDCG are bounded in [0, 1] across millions of generated cases) and pinned tests for cold-start behaviour.
- Reproducibility via a single
RANDOM_SEEDthat controls train/test splits, ALS init, and two-tower weights.
Tradeoffs and constraints
The Goodbooks-10k dataset has no rating timestamps, so the train/test split is per-user random-positive rather than temporal. A production deployment would need timestamps for a leakage-proof time split, an item popularity decay term, and an online learning loop for the long tail.
The two-tower model here is intentionally small (48-dim, 3 epochs, uniform random negatives) so the full leaderboard regenerates in under three minutes on CPU. A real deployment would push embedding dimension to 128 or higher, add side-feature towers (author, publisher, language, publication year), and train on GPU with popularity-weighted hard negatives.
Methodology
Appropriate use: portfolio demonstration of recommender systems engineering on a public dataset.
Inappropriate use: as a production reading recommendation service or as ground truth for editorial decisions; the dataset is from 2017 and item popularity has shifted since.
Limitations
The recommender operates on a static 2017 snapshot of Goodreads-style ratings. Cover images are loaded from the original Goodreads CDN and may rot. Ratings have no time component so the evaluation cannot test temporal drift.
The hybrid blend weights are hand-set, not learned end to end. Treating the blend weights as model parameters and training them with a small Adam loop on a validation set is the obvious next step.
What I would improve next
A learned hybrid blend with a small linear head trained on a held-out validation slice. A second two-tower model that consumes side features (author, language, publication year, tag bag-of-words) so the cold-item path stops relying purely on TF-IDF. A nightly ingestion job for new Goodreads exports so the catalogue stays fresh. A small offline canary that re-runs the evaluation harness against each new model artefact and refuses to promote it unless MAP@10 is within the bootstrap CI of the prior best.