Fair Lending Lab
A hypothesis testing and statistical inference case study on CFPB HMDA mortgage application data. Five preregistered hypotheses, parametric and non-parametric and permutation and bootstrap and Bayesian sensitivity validation, effect sizes with confidence intervals, BH-FDR and Bonferroni correction across the family, and explicit causal framing caveats throughout.
Evidence
Screenshots from the live dashboard against Massachusetts 2023 HMDA LAR data.
Sample findings
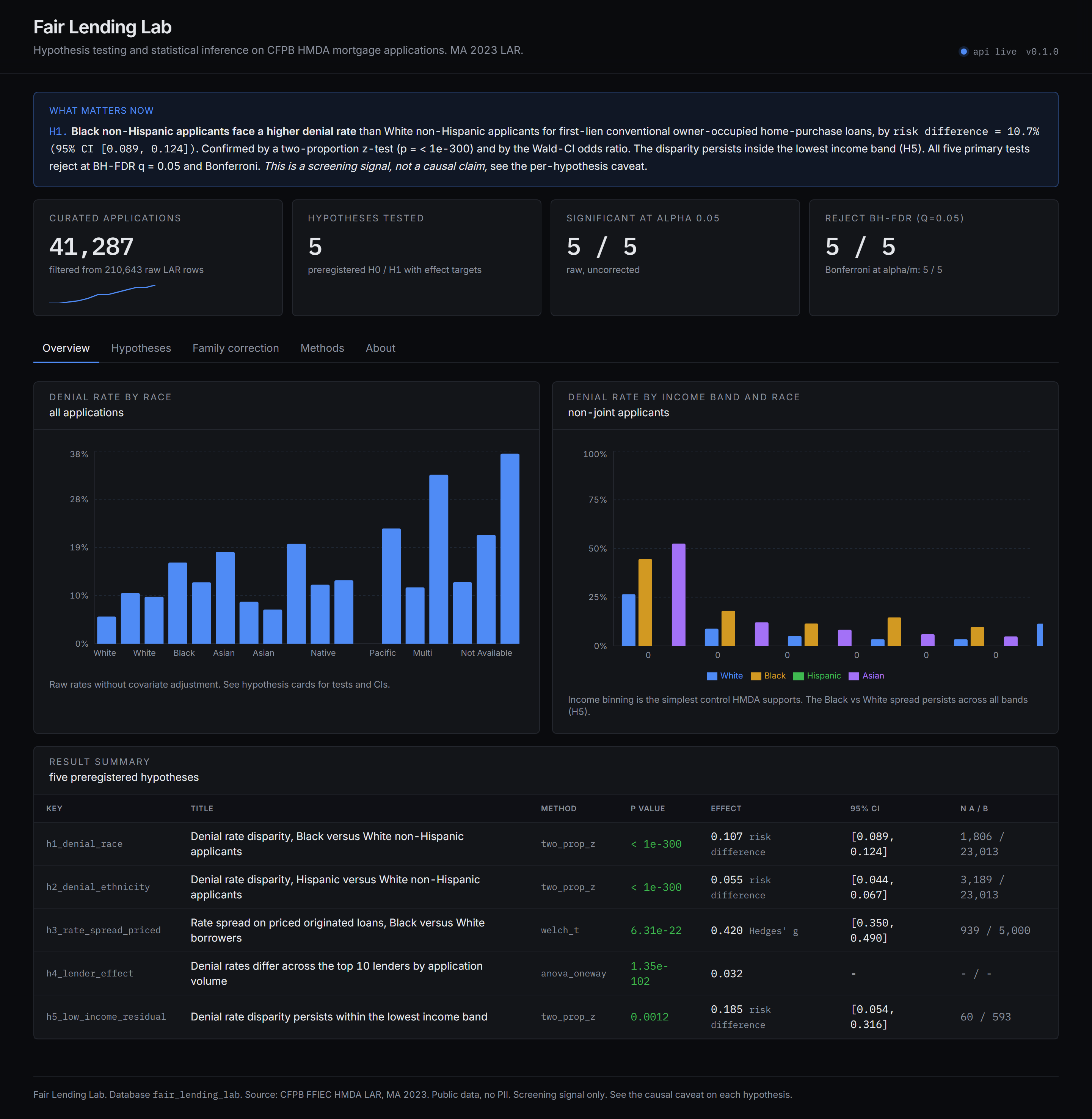
Observations from the scored Massachusetts 2023 prototype. These are screening signals in observed covariates, not findings of discrimination. See the causal framing section below.
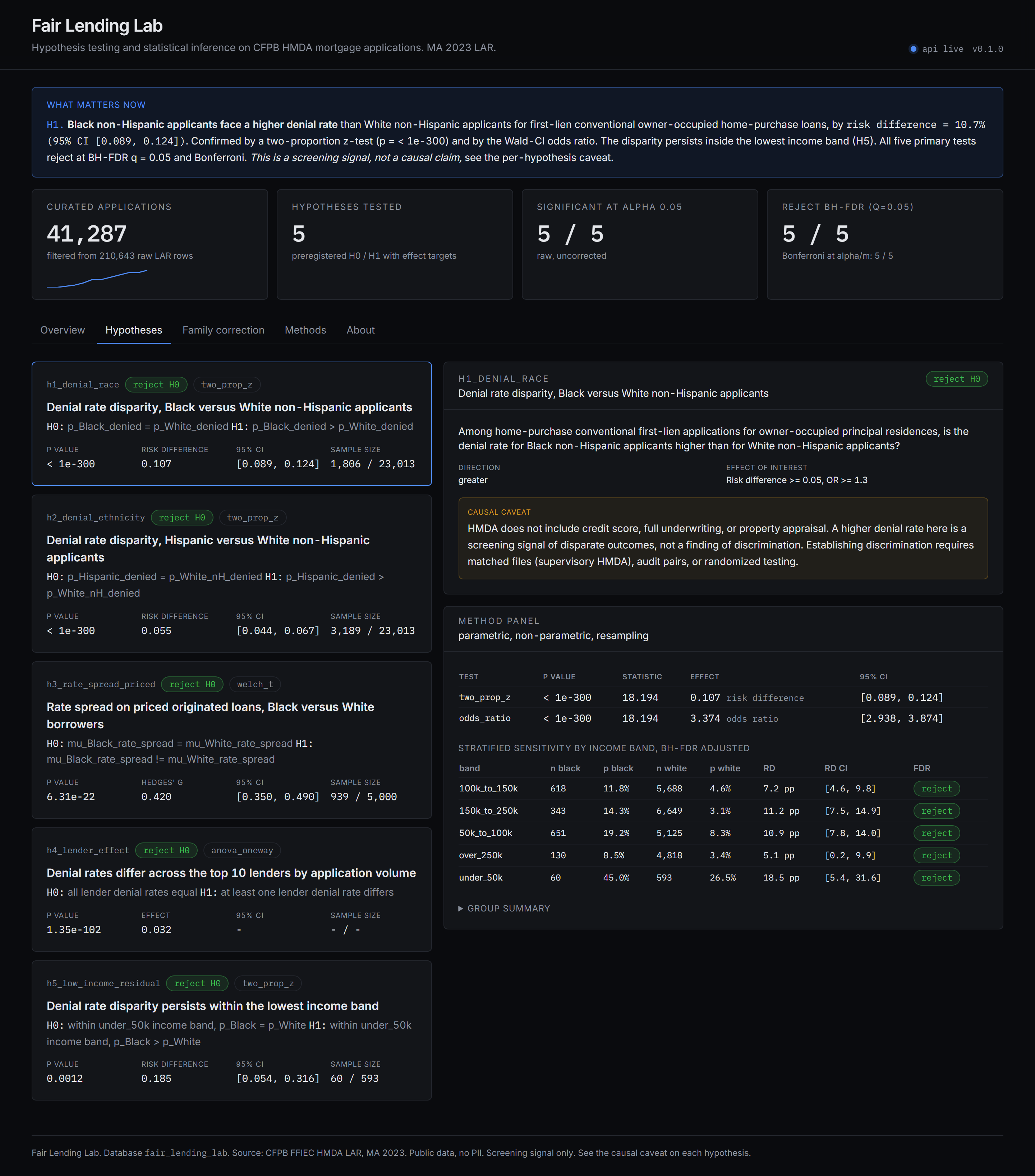
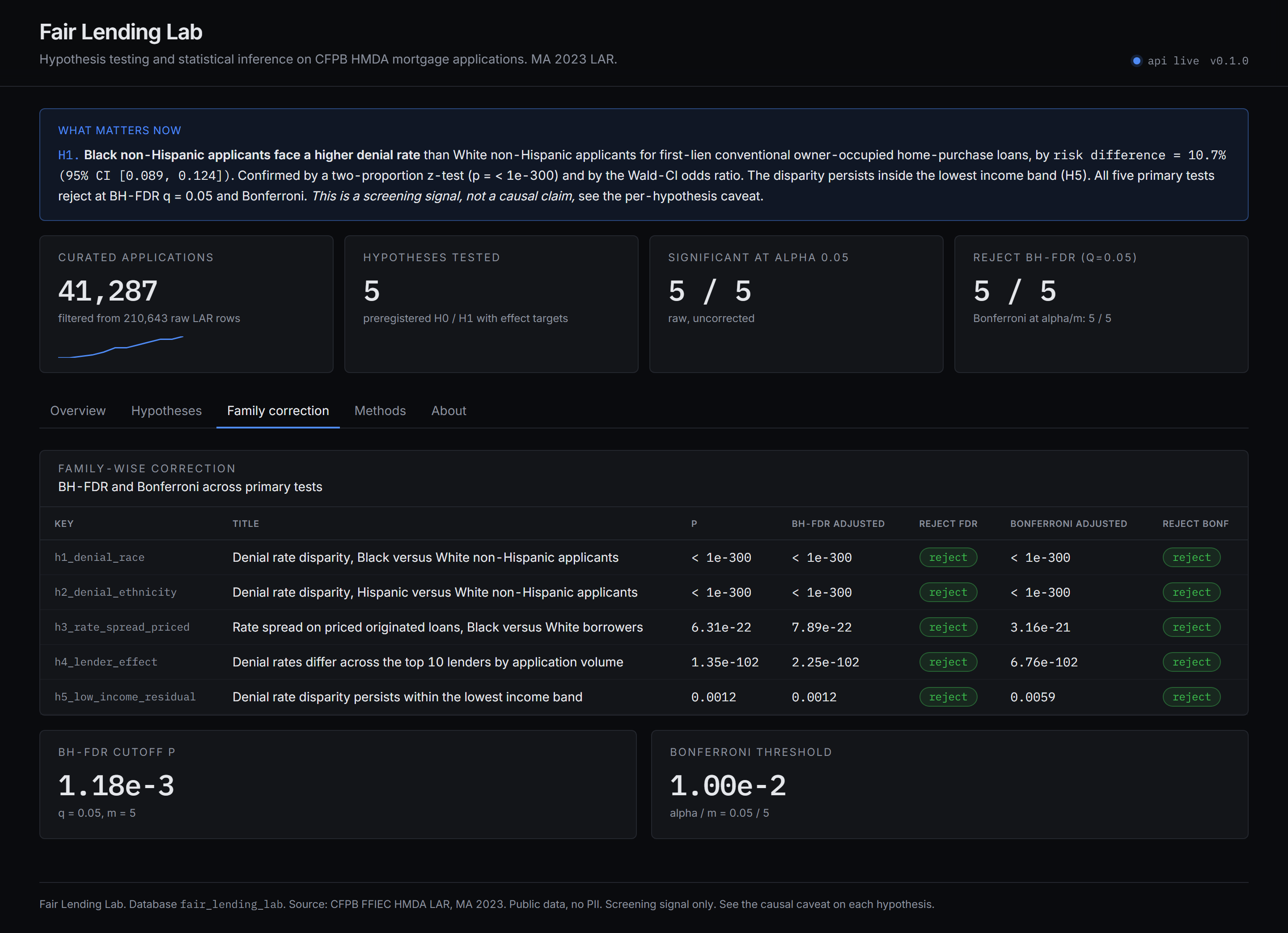
- H1 race disparity. Black non-Hispanic applicants face a risk difference of +10.7 percentage points (95% CI 8.9 to 12.4) versus White non-Hispanic applicants for first-lien conventional owner-occupied home-purchase loans (two-proportion z, p < 1e-300). Stratified by income band with BH-FDR adjustment, the disparity persists in every income band.
- H2 ethnicity disparity. Hispanic applicants face a +5.5 percentage point risk difference (95% CI 4.4 to 6.7) versus White non-Hispanic applicants (two-proportion z, p < 1e-300).
- H3 rate spread on priced loans. Among priced originated loans, Black borrowers carry a higher mean rate spread than White borrowers, Hedges g = 0.42 (95% CI 0.35 to 0.49), Welch t p = 6.3e-22, confirmed by Mann-Whitney and a 5,000 permutation test plus a conjugate Bayesian sensitivity.
- H4 lender effect. Denial rates differ materially across the top 10 lenders by application volume in this market, one-way F = 1.4e-102, eta squared = 0.032. Pairwise two-proportion z tests are reported with BH-FDR and Bonferroni adjustment.
- H5 low income residual. Within the lowest income band (under $50k applicant income), the Black vs White disparity is +18.5 percentage points (95% CI 5.4 to 31.6, p = 0.001), a screening signal that the gap is not fully explained by a coarse income control.
- Family-wise correction. All five primary tests reject at BH-FDR q = 0.05 and at Bonferroni alpha / m.
Problem
The HMDA Loan Application Register is one of the largest public datasets in financial services. Reading it well requires more than a t test. Sample sizes are big enough that any difference becomes statistically significant, so power analysis, effect sizes, multiple-comparison correction, and explicit causal framing are what separate a credible BI analysis from a misleading one.
The project needed to demonstrate how a senior data analyst structures inferential work on a sensitive policy dataset: preregistered hypotheses with directional H0/H1, multiple statistical methods that have to agree, family-wise correction, effect sizes with confidence intervals, and a disciplined separation between association and causation.
Users or audience
The primary audience is recruiters, hiring managers, and technical interviewers for senior data, BI, and fair-lending analytics roles. The methodology is the same one a fintech compliance team or a CFPB analyst would use as a screening pass before pulling matched supervisory data.
The dashboard is portfolio methodology. It is not a regulatory finding, a discrimination claim against any lender or applicant pool, or a substitute for the matched-data analyses used in actual fair-lending review.
Solution
A Python backend ingests the CFPB FFIEC HMDA LAR for a chosen state and year, curates first-lien conventional owner-occupied home-purchase applications into a Postgres fact table, and runs five preregistered hypotheses through a layered method stack (parametric, non-parametric, permutation, bootstrap, Bayesian sensitivity). Results are cached as JSONB and exposed by a read-only FastAPI service.
A Next.js frontend renders the same data in a near-black analyst console: KPI tiles with sparklines, a "what matters now" callout, per-hypothesis cards with primary and secondary tests, posterior plot, stratified sensitivity tables, family-wise correction view, and a methods tab. Backend deploys to a Linux VPS behind nginx via systemd, frontend deploys to Cloudflare Pages.
Architecture
Data flow
The pipeline pulls a state-year LAR from the CFPB Data Browser CSV endpoint, projects the 99 raw columns down to the 34 needed for analysis, and COPYs the raw rows into a Postgres staging table. A curated SQL step filters to comparable applications and engineers analysis columns (race rollup, ethnicity rollup, income band, loan amount band, priced-loan flag, denial flag).
Each preregistered hypothesis pulls its own slice, runs the full method stack, writes a primary plus secondary result block plus assumption checks plus power block to the analysis-runs log, and upserts a denormalized JSON payload to the results cache. The API serves the cache, the dashboard hydrates from the API on load.
Tools used
Key features
- Five preregistered hypotheses with explicit H0, H1, direction, and pre-test effect-of-interest target.
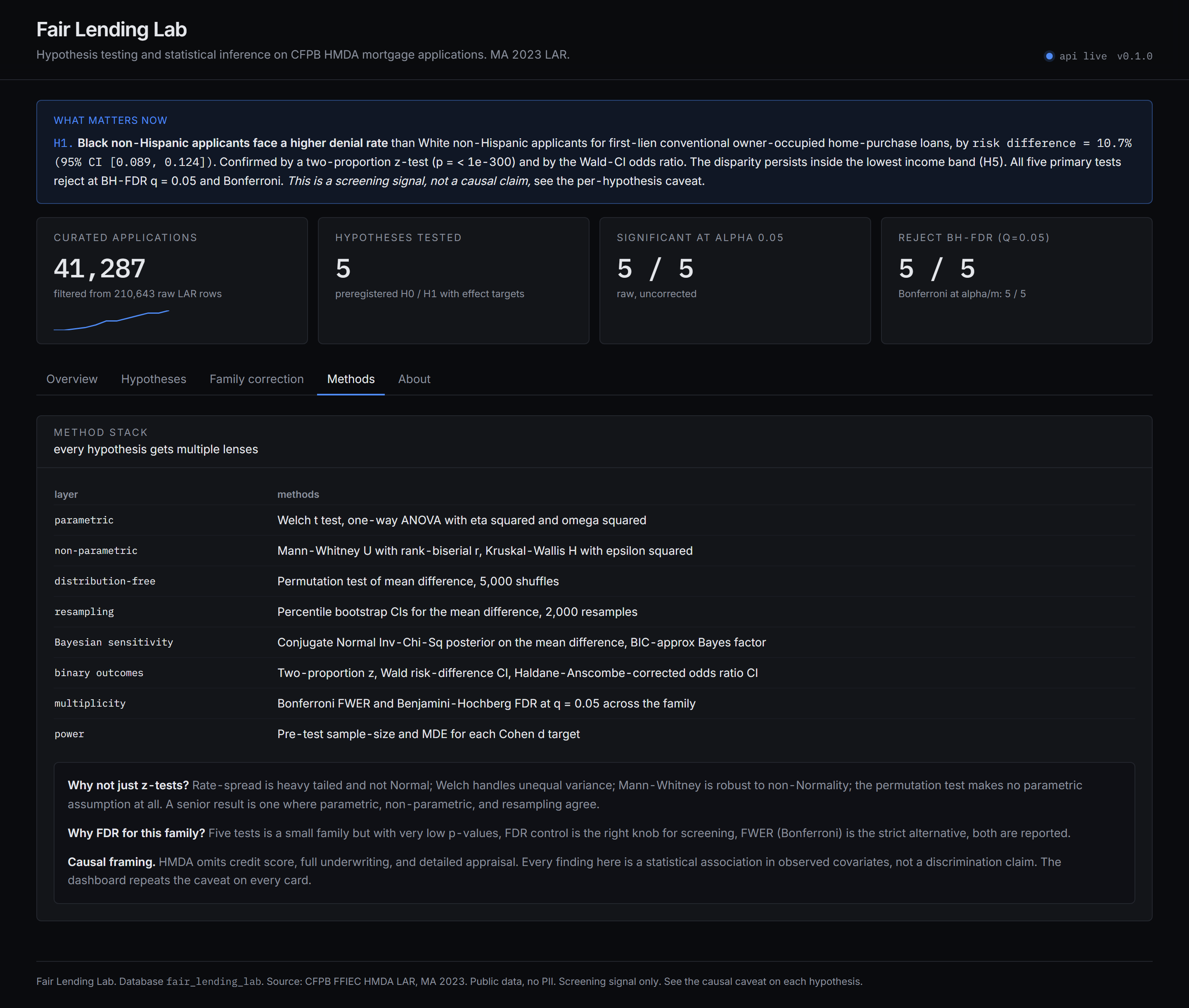
- Method stack: Welch t, Mann-Whitney with rank-biserial r, one-way ANOVA with eta squared and omega squared, Kruskal-Wallis with epsilon squared, two-proportion z, Wald risk-difference CI, Haldane-Anscombe-corrected odds ratio CI, 5,000 sample permutation test, 2,000 sample percentile bootstrap, and a conjugate Normal Inv-Chi-Sq Bayesian sensitivity with BIC-approximation Bayes factor.
- Family-wise correction: Benjamini-Hochberg FDR at q = 0.05 and Bonferroni FWER at alpha / m across the five primary tests.
- Stratified sensitivity for the headline H1 across income bands, with BH-FDR adjustment over strata.
- Pairwise post-hoc tests for the lender-effect ANOVA, with BH-FDR and Bonferroni adjustment over the 45 pairwise comparisons.
- Power and minimum detectable effect reported for every test so a non-rejection is interpretable.
- Causal framing caveat on every hypothesis: HMDA omits credit score and full underwriting, so reported disparities are screening signals, not findings of discrimination.
- Deterministic seed across NumPy, SciPy, permutation, bootstrap, and pandas sampling; the notebook reproduces bit identically.
- Pytest plus Hypothesis property tests on the stats helpers, plus a registry sanity test that scans hypothesis text for forbidden characters.
- CI workflow that lints with ruff, runs pytest against a real Postgres service, builds the Next.js frontend, and scans the repo for forbidden em or en dashes.
Methodology and causal framing
Appropriate use: portfolio demonstration of senior-grade hypothesis testing on a real public dataset, including power analysis, effect-size reporting, multiple-method validation, multiplicity correction, and explicit limitation framing.
Inappropriate use: regulatory determinations, discrimination findings against any specific lender, legal claims against any borrower group, or any operational decision that would normally require matched supervisory data plus loan-file audit pairs.
What the analysis can claim. The reported disparities are statistical associations in HMDA-observed covariates. They are consistent with a real residual disparity after partial adjustment, with omitted-variable bias from credit-quality features HMDA does not contain, and with selection effects in which lenders different groups apply to. The job here is to surface that pattern with calibrated uncertainty, not to assign cause.
What it would take to claim discrimination. Matched supervisory HMDA with credit-bureau records, loan-file review, audit-pair testing, or a counterfactual design. None of those are in scope for a public-data portfolio project, which is why every hypothesis card in the dashboard carries the same caveat in plain language.
Results
Headline numbers from the live Massachusetts 2023 dataset. Re-runs against any other state or year are a one-line config change.
Limitations
HMDA omits credit score, full underwriting detail, property appraisal, and post-application history. Massachusetts 2023 is one state-year of one product line. The disparities here are statistical associations, not causal findings.
Restricting H3 to priced originated loans is a conditioning-on-collider risk: the same underwriting that produces a higher denial rate may also push observed borrowers toward the priced segment. The result is informative about the priced-loan population, not about the underlying borrower population.
What I would build next
Add a propensity-score matched-pair sensitivity analysis on the observed covariates, a logistic regression with all available HMDA controls, and an MSA-level fixed-effect model. Add multi-year ingest so trend tests (did the disparity move after a specific rule change) become single-config queries. Extend to additional state-year files by parameter; the pipeline is dataset agnostic.