Grid Intelligence
A live public-data grid analytics platform with API ingestion, scheduled data pipelines, time-series modeling, anomaly scoring, forecasting, pipeline health, and dashboard delivery.
Problem
Public grid data is distributed across multiple sources, arrives on different schedules, and is difficult to scan quickly without a modeled data layer and a focused interface.
The project needed to show real analytics delivery, not just charts: ingestion, transformation, API delivery, dashboard design, data freshness, and clear limitations.
Users or audience
The primary audience is recruiters, hiring managers, and technical interviewers evaluating practical data engineering, analytics modeling, API design, and dashboard delivery skills.
The dashboard is built for portfolio demonstration using public data. It is not designed for official operations or reliability decisions.
Solution
Grid Intelligence ingests public grid and weather data, stores it in a time-series layer, models it into dashboard-ready tables, calculates forecasts and anomaly scores, and serves the output through a FastAPI backend consumed by a live dashboard.
The result is a single portfolio project that demonstrates the full path from raw external data to usable analytical product.
Architecture
Data flow
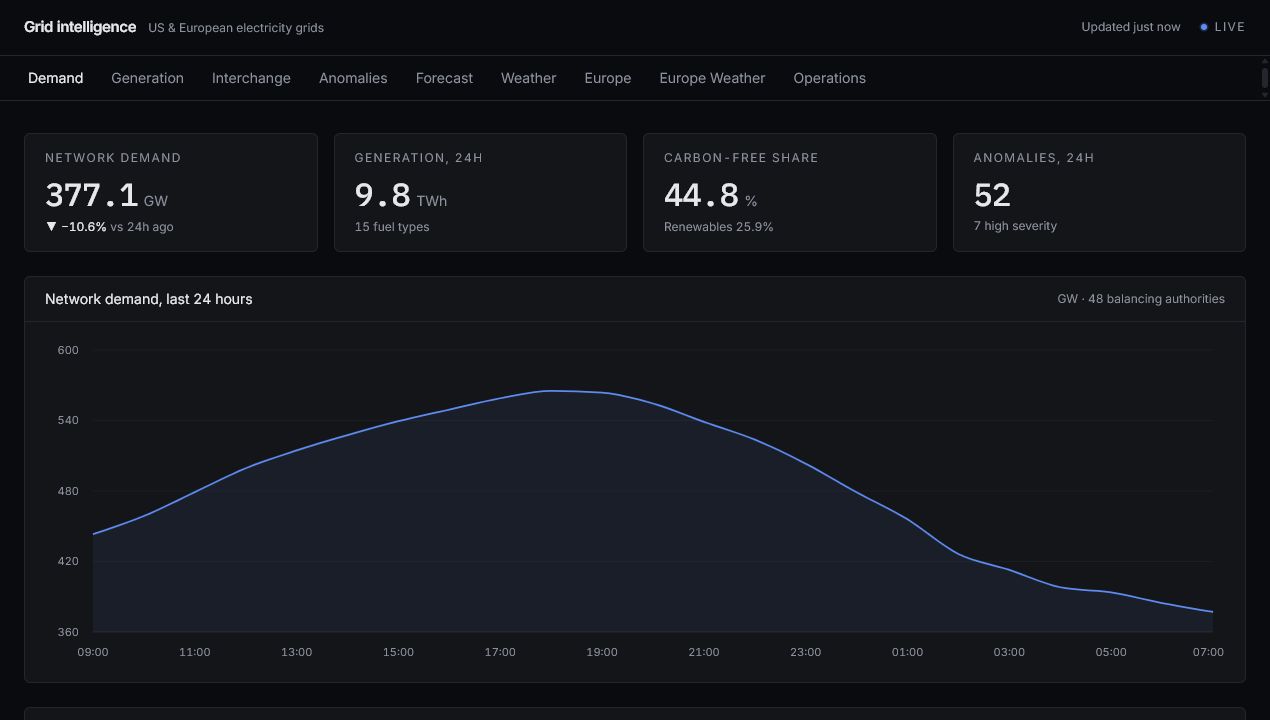
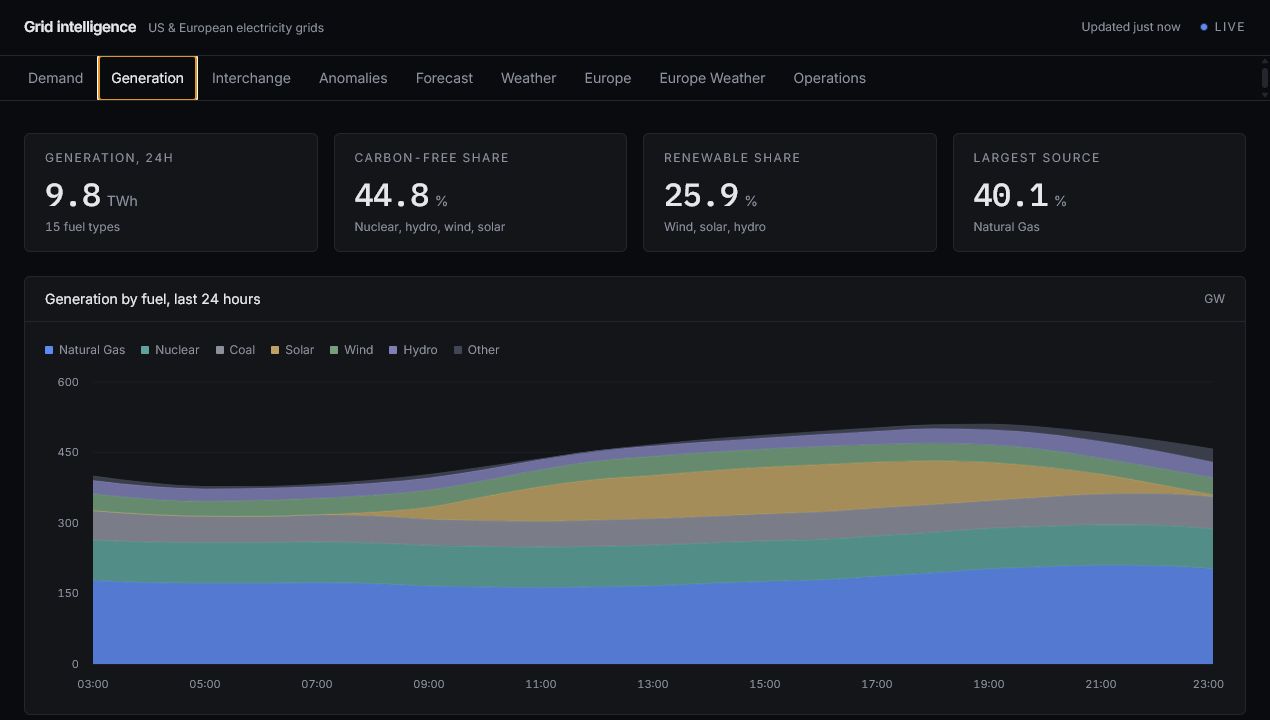
External APIs feed scheduled ingestion jobs. Raw records are stored with timestamps and source metadata. Transformations create dashboard-ready views for demand, generation mix, forecast context, anomaly scoring, freshness, and pipeline health.
The API layer exposes focused endpoints so the dashboard can load summary cards, charts, anomaly panels, and health indicators without embedding data logic in the front end.
Tools used
Key features
- Public-data API ingestion with scheduled refresh patterns.
- Time-series modeling for grid demand, generation, and trend analysis.
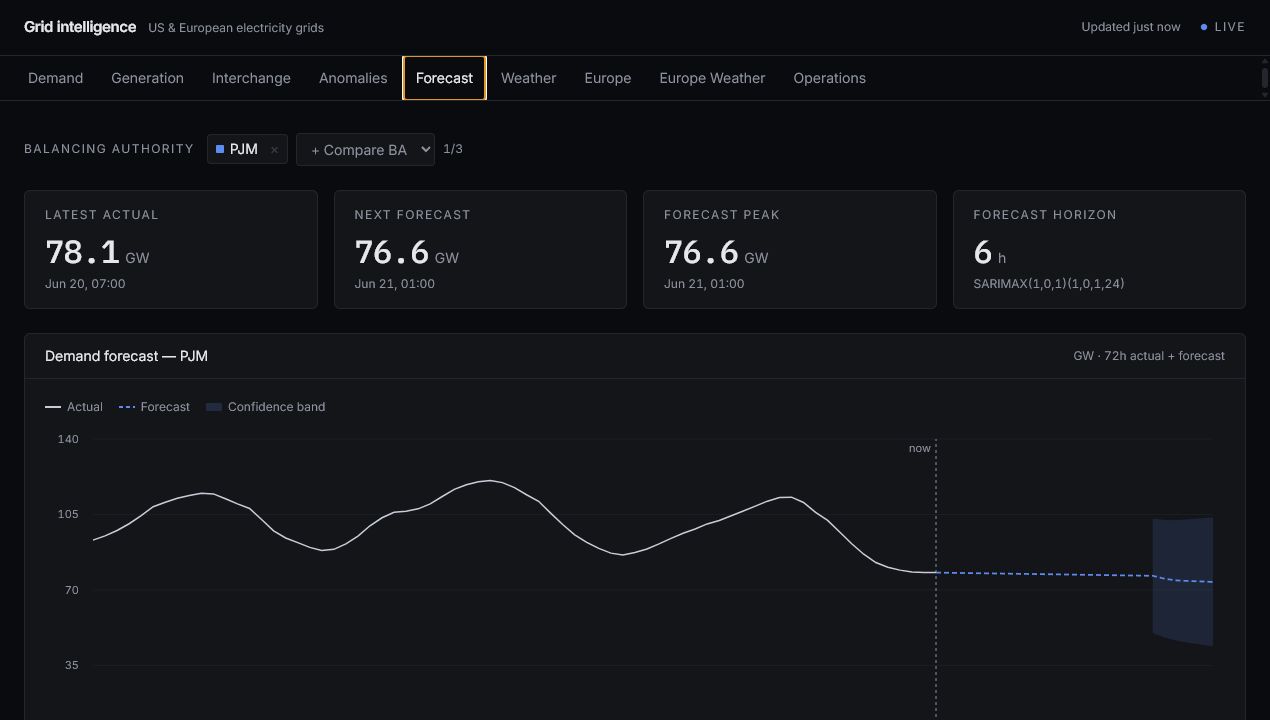
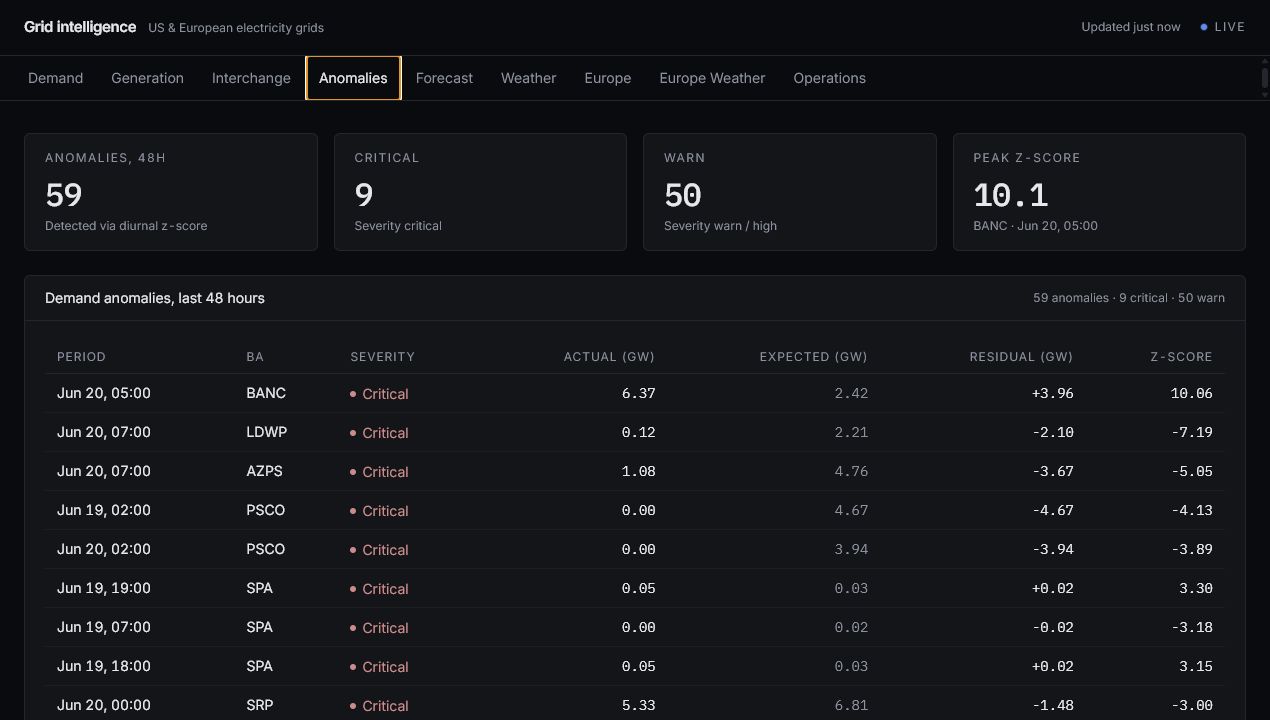
- Forecasting and anomaly scoring presented with operational context.
- Dashboard sections for current state, forecast, anomalies, generation, and pipeline health.
- Data freshness indicators so reliability is visible to the viewer.
Tradeoffs and constraints
The project favors clear portfolio evidence over exhaustive domain coverage. It uses public data and transparent modeling choices instead of restricted operational feeds or proprietary assumptions.
Forecasting and anomaly scoring are demonstration models. They are useful for showing pipeline design and analytical thinking, but they are not official reliability or planning tools.
Methodology
Appropriate use: portfolio demonstration of public-data engineering, analytics modeling, and dashboard delivery.
Inappropriate use: operational grid decision-making, trading, regulatory analysis, or official reliability assessment.
Results or expected value
The finished platform demonstrates full-stack analytics delivery: public data ingestion, modeling, ML-assisted analytics, API design, visual reporting, deployment, and limitation-setting.
Limitations
The dashboard depends on public source availability and source cadence. Some signals may be delayed, revised, or unavailable depending on upstream data behavior.
The project is intentionally scoped as a portfolio analytics system. It should not be treated as an authoritative operational grid system.
What I would improve next
I would add deeper data quality monitoring, more explicit model evaluation, clearer incident history for ingestion failures, and more documentation around each source and transformation.